
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- deep learning
- python
- 데이터분석가
- 데이터 분석가
- data analyst
- Tableau
- Data Science
- 파이썬
- pandas
- Deeplearning
- ai
- numpy
- AISCHOOL
- CNN
- machinelearing
- MachineLearning
- Data Scientist
- EDA
- 데이터 사이언티스트
- data
- Machine Learning
- 멋쟁이사자처럼
- 범죄통계
- DNN
- machineleaning
- SQL
- data analysis
Archives
- Today
- Total
Molybdenum의 개발기록
[TIL] 9일차_PYTHON_Correlation_Cofficient_Code 본문
▶상관계수 ( Correlation Coefficient )
- numpy를 이용하여 데이터의 상관계수를 구합니다.
- python 코드와 numpy의 함수의 속도차이를 비교합니다.
▶ Index
- 분산
- 공분산
- 상관계수
- 결정계수
▶ 분산(variance)
- 1개의 이산정도를 나타냅니다.
- 편차제곱의 평균
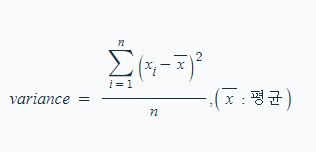
▶ 공분산(convariance)
- 2개의 확률변수의 상관정도를 나타낸다.
- 평균 편차곱
- 방향성은 보여줄 수 있으나 강도를 나타내는데는 한계가 있다.
- 표본 데이터의 크기에 따라서 값의 차이가 크다는 단점이 있다.
- 공분산이 +인경우 : 두 변수가 같은 방향으로 변화(하나가 증가면 다른하나도 증가)
- 공분산이 -인경우 : 두 변수가 반대방향으로 변화(하나가 증가면 다른하나는 감소)
- 공분산이 0인경우 : 두 변수가 독립, 즉 한 변수의 변화로 다른 변술의 변화 예측 X
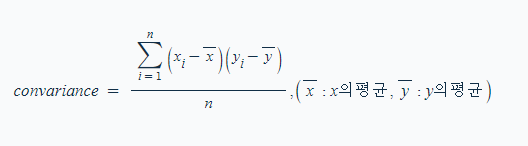
- 자유도
def covariance(x, y):
cov = 0
x_ = sum(x) / len(x)
y_ = sum(y) / len(y)
for xi, yi in zip(x, y):
cov += (xi - x_) * (yi - y_)
return cov / (len(x) - 1)covariance(data1, data2), covariance(data1, data3)
(93.75, -87.5)np.cov(data1, data2)[0, 1], np.cov(data1, data3)[0, 1]
(93.75, -87.5)
- 공분산의 한계 : 방향성은 보여줄 수 있으나, 강도는 보여줄 수 없음
data4 = [data * 10 for data in data1]
data5 = [data * 10 for data in data3]
data1, data3, data4, data5
([80, 85, 100, 90, 95],
[100, 90, 70, 90, 80],
[800, 850, 1000, 900, 950],
[1000, 900, 700, 900, 800])covariance(data1, data3), covariance(data4, data5)
(-87.5, -8750.0)
▶ 상관계수(correlation coefficient)
- 공분산의 한계를 극복하기 위해서 만들어진다.
- -1 ~ 1까지의 수를 가지며 0과 가까울수록 상관도가 적음을 의미한다.
- x의 분산과 y의 분산을 곱한 결과의 제곱근을 나눠주면 x나 y의 변화량이 클수록 0에 가까워진다.
- 참고 : https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.corrcoef.html
numpy.corrcoef — NumPy v1.13 Manual
x : array_like A 1-D or 2-D array containing multiple variables and observations. Each row of x represents a variable, and each column a single observation of all those variables. Also see rowvar below. y : array_like, optional An additional set of variabl
docs.scipy.org

- 최종 상관계수

- 1과 가까울수록 강한 양의 상관관계
- -1과 가까울수록 강한 음의 상관관계
- 0과 가까울수록 관계없음
▶ 결정계수(cofficient of determination : R-squared)
- x로부터 y를 예측할 수 있는 정도
- 상관계수의 제곱 (상관계수를 양수화)
- 수치가 클수록 회기분석을 통해 예측할 수 있는 수치의 정도가 더 정확하다.
- 공분산 : 방향성 O, 강도X
- 상관계수 : 방향성 O, 강도O
- 결정계수 : 방향성 X, 강도O
출처-멋쟁이사자처럼_AISCHOOL_박두진강사님
'TIL' 카테고리의 다른 글
| [TIL] 10일차 PYTHON_Class_IO_01 (0) | 2023.03.03 |
|---|---|
| [TIL] 9일차_QUIZ (0) | 2023.03.03 |
| [TIL] 9일차_PYTHON_Decorator (0) | 2023.03.03 |
| [TIL] 9일차_PYTHON_Class (0) | 2023.03.03 |
| [TIL] 8일차_PYTHON_Function_03 (0) | 2023.03.03 |
Comments