
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- python
- Tableau
- EDA
- Deeplearning
- Data Scientist
- data
- AISCHOOL
- 데이터분석가
- deep learning
- 파이썬
- machinelearing
- 데이터 분석가
- MachineLearning
- machineleaning
- 범죄통계
- Data Science
- ai
- data analysis
- 데이터 사이언티스트
- CNN
- 멋쟁이사자처럼
- DNN
- Machine Learning
- data analyst
- numpy
- SQL
- pandas
- Today
- Total
Molybdenum의 개발기록
[TIL] 72일차_Deep Learning_CNN_VGGNet&ResNet 본문
2014, VGGNet
: AlexNet(2012)dml 8-layers 모델보다 깊이가 2배 이상 깊은 네트워크의 학습에 성공(layer)하였다.
=> 이를 통해 ImageNet Challenge에서 AlexNet의 오차율을 절반(16.4 > 7.3)으로 감소하였다.
- 16-19개 layer와 같이 깊은 신경망 모델의 학습을 성공 => 3x3 필터를 사용했기 때문이다. layer를 깊게 쌓는 것이 VGG의 핵심이며 layer의 깊이가 어떤 영향을 주는지 6개 구조에 대한 연구로 시작되었다.
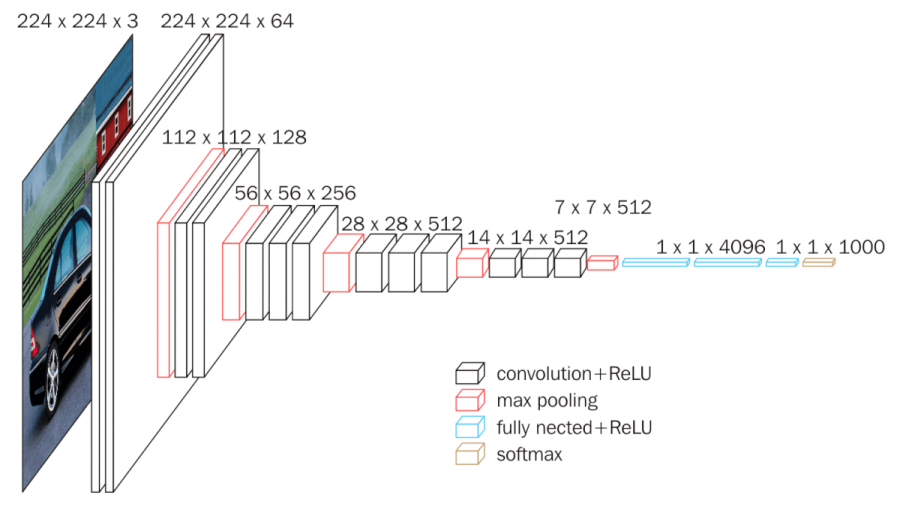
- 모든 합성곱층(Convolutional layer)에서 3x3필터만을 사용하는가 => 2개의 3x3 합성곱을 중첩하면 1개의 5x5 합성곱의 수용 영역과 동일하기 때문이다. 층마다 활성화 함수를 사용할 수 있어서 결정 함수의 비선형성이 증가하며 파라미터 수도 줄어드는 효과로 학습 속도가 향상된다.
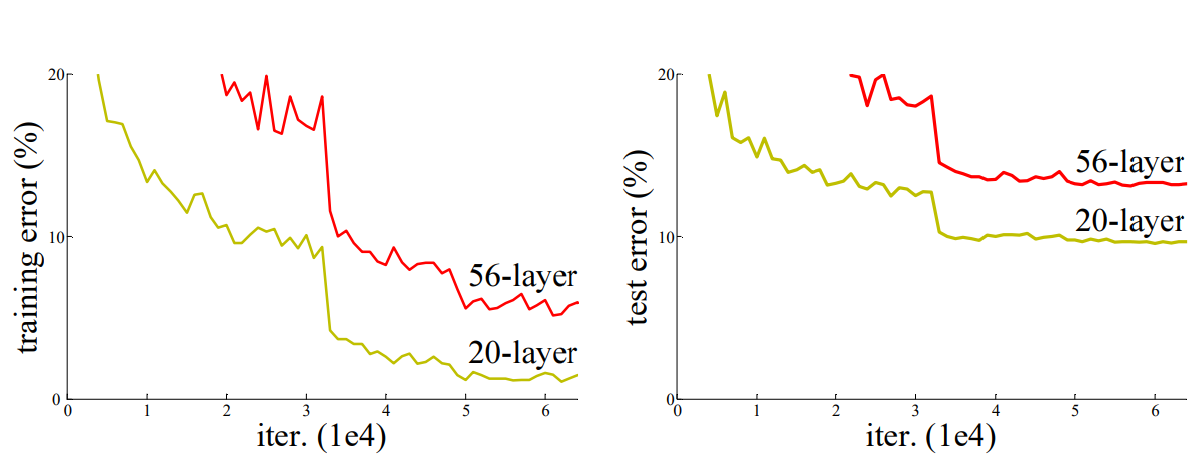
2015. ResNet
: Residual Block에서 유래되었으며 깊은 네트워크를 학습시키기 위한 방법으로 잔여학습(residual learning)을 제안하였으며 깊은 레이어의 성능이 좋아졌다.
- 깊은 층 구성 문제 : VGGNet을 통해 딥러닝에서 기본적으로 층(layer)이 깊어지면 성능이 더 좋아진다고 생각되었는데 19 layer(VGGNet)보다 더 망을 깊게 설게하여 테스트 하였으나, 20 layer보다 56 layer의 결과가 더 나빴다.
=> 층(layer)이 깊어지면 기울기 소실(gradient vanishing)과 폭주(exploding) 또는 성능저하(degradation)이 발생하였다.
ResNet은 잔차(Residual)라는 사전적 의미를 활용해 성능 저하(Degradation)을 해결하였다.
- 잔여블록(residual block) : 네트워크의 최적화(optimization)난이도를 낮춘다
=> 기존의 신경망은 H(x) = x가 되도록 학습하였으나, 한 번에 H(x)를 학습하는 것은 어려워 대신 f(x)=H(x)-x를 학습하였다. H(x) 처럼 전체를 학습하는 것보다 F(x)와 x를 분리해서 계산하여 난이도를 낮춘다.
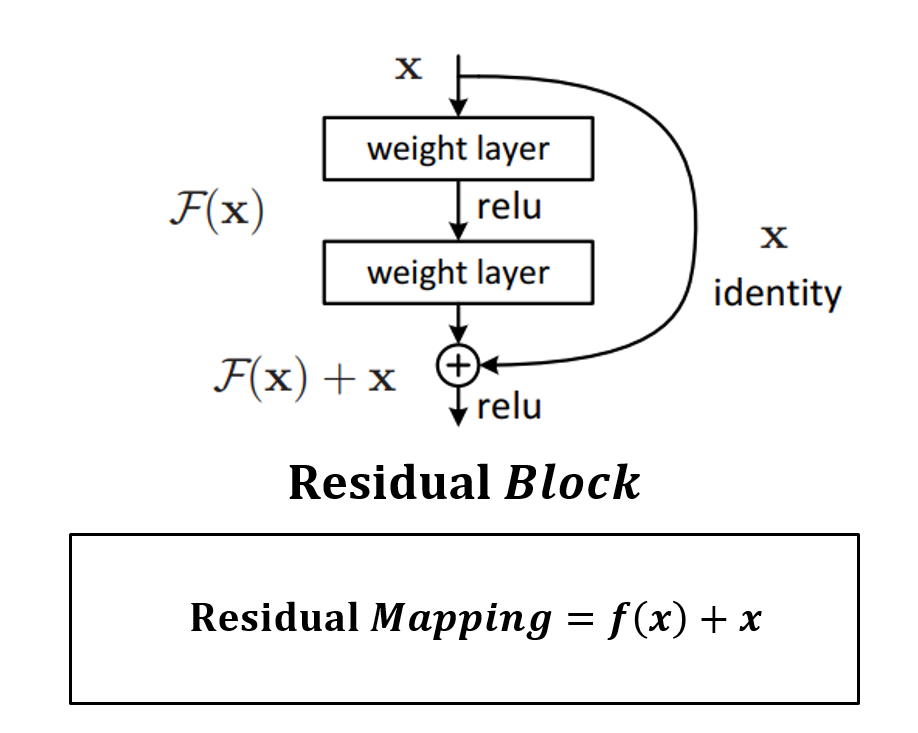
- shortcut : 기울기 소실을 방지하며 학습 수행하는 역할을 한다. 2개의 합성곱층마다 잔여블록으로 shortcut을 만들어 차원을 변화시키며 레이어를 중첩한다. 이를 통해 FLOPs(계산복잡도)가 VGG-19 모델의 196억 FLOPs에서 ResNet 모델의 36억 FLOPs로 감소하였다.
- identity shortcut : 입력과 출력의 차원이 같을 때 일반적으로 사용된다.
- projection shortcut : 입력돤과 출력단의 차원이 다를 때, 차원 증가 테크닌이 가미된 shortcut
- bottleneck residual block : ResNet50 이상에서는 연산량을 줄이기 위해 GoogLeNet에서 사용했던 bottleneck residual block을 중첩사용한다.
=> 1x1 합성곱(Convolution)의 파라미터는 연산량이 작기 때문에 Feature Map을 줄이거나 키울 때 사용한다
- 배치정규화(BN) : 기울기 소실과 폭주문제를 방지할 수 있어 학습과정을 전체적으로 안정화하는 방법이다. 평균과 분산을 조정하는 과정이 별도의 과정이 아닌, 신경망 안에 포함되어 학습시 평균과 분산을 같이 조정한다.
=> Batch Normalization(BN)을 잔여블록에 사용 하였으며, Conv-BN-ReLU 순으로 배치한다.
2017. SENet : Squeeze_and_Excitation_Networks
: 성능은 유지하면서 딥러닝 모델 파일의 크기를 줄이는 것이 목적이다. 또한 추가적인 계산량이 적어 SE block을 추가하면서 생기는 파라미터의 증가량에 비해 모델 성능, 향상도가 매우크다
SE block의 가장 큰 장점은 이미 존재하는 CNN architecture에 붙여서 사용할 수 있다는 점이다.
Q. 왜 딥러닝 모델 파일의 크기를 줄이려고 할까
=> 1) 분산환경에서의 학습이 용이하며, 2) 말단 기기로 모델 파일을 전송하기에 유리하고, 3) 저사양 화로에서 사용이 가능하다.
- SE block(Squeeze-Excitation block) : 컨볼루션을 통해 생성된 특성을 채널당 중요도를 고려해서 재보정한다.
- Squeeze(Fsq) : GAP를 사용하여 각 채널들의 중요한 정보만 추출하여 채널 하나당 대표되는 스칼라 값을 생성한다.
- Excitation(Fex) : 추출된 정보를 채널 간 의존성(channel-wise dependencies)으로 재보정하여 가중치를 계산한다.
CNN 과정
model = models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), # 첫레이어 input_shape설정
tf.keras.layers.MaxPooling2D((2, 2)), # pool_size 는 윈도우의 크기를 의미하며 수직, 수평 축소 비율을 지정
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), # 필터의 수=64, 커널사이즈=(3,3)
tf.keras.layers.MaxPooling2D((2, 2)), # (2, 2)이면 출력 영상 크기는 입력 영상 크기의 반으로 줄어듬
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), # 필터의 수=64, 커널사이즈=(3,3)
tf.keras.layers.Flatten(), # 추출된 특징을 전결합층에 전달하기 위해 배열 형태로 flat(흑백2D or 컬러3D → 1D)
tf.keras.layers.Dense(64, activation='relu'), # 클래스 분류를 위한 완전 연결 계층(FC) 추가
tf.keras.layers.Dropout(0.2), # 과대적합을 피하기 위해 드롭아웃을 레이어에 적용하여 20%를 무작위로 드롭아웃
# 0.1, 0.2, 0.4 등의 값을 입력하면 해당 층에서 출력 단위의 10%, 20% 또는 40%를 임의로 제거
tf.keras.layers.Dense(10, activation='softmax') ]) # 10개의 노드를 소프트맥스 함수로 확률 반환(전체 합=1)
- Conv2D
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid', input_shape=(28, 28, 1),
data_format=None, dilation_rate=(1, 1), groups=1, activation=None,
use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None, **kwargs)filters : 컨볼루션 필터의 수 >> 필터 수 = 특징맵 수
kernel_size : 컨볼루션 커널의 (행, 열) >> 필터 사이즈
padding : 경계 처리 방법
- ‘valid’ : 유효한 영역만 출력이 됩니다. 따라서 출력 이미지 사이즈는 입력 사이즈보다 작습니다.
- ‘same’ : 출력 이미지 사이즈가 입력 이미지 사이즈와 동일합니다.
input_shape : 모델에서 첫 레이어일 때만 정의하면 됨 (batchSize, height, width, channels)
activation : 활성화 함수 설정합니다.
- ‘linear’ : 디폴트 값, 입력뉴런과 가중치로 계산된 결과값이 그대로 출력
- ‘relu’ : rectifier 함수, 은닉층에 주로 사용
- ‘sigmoid’ : 시그모이드 함수, 이진 분류 문제에서 출력층에 주로 사용
- ‘softmax’ : 소프트맥스 함수, 다중 클래스 분류 문제에서 출력층에 주로 사용
- MaxPool2D
tf.keras.layers.Flatten(
data_format=None, **kwargs)- Flatten
tf.keras.layers.Flatten(
data_format=None, **kwargs)data_format : 문자열, channels_last(기본값) 또는 channels_first. 입력에서 차원의 순서
- Dense
tf.keras.layers.Dense(
units, activation=None, use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs)units : 출력 값의 크기
activation : 활성화 함수
use_bias : 편향(b)을 사용할지 여부
kernel_initializer : 가중치(W) 초기화 함수
bias_iniotializer : 편향 초기화 함수
kernel_regularizer : 가중치 정규화 방법
bias_regularizer : 편향 정규화 방법
activity_regularizer : 출력 값 정규화 방법
kernel_constraint : 가중치에 적용되는 부가적인 제약 함수
bias_constraint : 편향에 적용되는 부가적인 제약 함수
* 출력층
회귀의 출력
>> tf.keras.layers.Dense(1)
이진분류의 출력
>> tf.keras.layers.Dense(1,activation=’sigmoid’)
다중클래스 출력
>> tf.keras.layers.Dense(n,activation=’softmax’)
학습 전 데이터 입력
loss='categorical_crossentropy'일 때 종속변수 데이터(y)의 전처리 : 레이블을 범주형으로 인코딩한다. 활성화 함수를 적용하려면 y값이 숫자 0과 1로 이루어져 있어야 적용이 가능하다.
from tensorflow.keras.utils import to_categorical
# to_categorical는 클래스 벡터(정수)를 이진 클래스 행렬로 변환
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)'TIL' 카테고리의 다른 글
| [TIL] 76일차_Transformer (0) | 2023.04.24 |
|---|---|
| [TIL] 73일차_Deep Learning_RNN (0) | 2023.04.19 |
| [TIL] 71일차_Deep Learning_CNN_ILSVRC Algorithm (0) | 2023.04.19 |
| [TIL] 71일차_Deep Learning_CNN (0) | 2023.04.12 |
| [TIL] 71일차_Deep Learning_Modeling (0) | 2023.04.12 |



